

AgentOps helps developers see inside their AI agents by logging every prompt, action, and cost. This review explains how it works, its features, setup, and why it’s becoming the go-to debugging tool for AI developers.
What Is Metadata? We Answer All Your Questions in This Guide!

Welcome to our guide: what is metadata. Think of metadata as the “labels” that help you sort and understand everything in your digital world. Just like you might label a box to know what's inside without opening it, metadata gives a quick glimpse into what information a file, photo, or document holds. In this guide, we'll chat about what metadata is, why it's so useful, who can benefit from knowing about it, and what topics we’ll cover together.
What Is Metadata's Definition?

Metadata is simply data about data. It’s information that describes other information. For example, when you take a photo with your smartphone, metadata might include the date the photo was taken, the location, and the camera settings. All of this helps you sort through your pictures and even share them more effectively.
Why Metadata Matters
Metadata might seem like a small detail, but it plays a huge role in keeping our digital lives organized. Think about your computer’s file system: without file names, creation dates, or file types, finding what you need would be like searching for a needle in a haystack.
- Organization: Metadata helps keep files neatly arranged. For instance, your digital photos might be sorted by date or location, making it easier to create albums or share memories with friends and family.
- Searchability: Ever used the search function on your phone or computer? That’s metadata at work. By tagging your files with keywords or descriptions, you can quickly locate that important document or cherished photo without scrolling endlessly.
- Data Management: For businesses and organizations, metadata is essential for managing large amounts of information. It’s like having an index in a book—without it, finding the right chapter would take forever. From digital libraries to vast media archives, metadata ensures that every piece of data is easy to find and use.
Real-world examples can make these points clearer. Consider digital photos: every image might carry metadata about when and where it was taken, what camera was used, and even the settings. This helps not only in organizing albums but also in editing and printing photos later on. Similarly, for music files, metadata might include the artist, album, and genre, so your music player can automatically sort your favorite tunes.
Metadata Analysis: Who This Guide Is For:
This guide is designed for anyone curious about metadata—whether you're just starting out or looking to sharpen your skills. Here are a few groups who might find it especially useful:
- Beginners: If you’ve ever wondered what those extra details in your photos or documents are, this guide is for you.
- Digital Librarians and Archivists: Those who manage large collections of information will find practical tips on organizing and retrieving data.
- Content Creators: Bloggers, video producers, and photographers can learn how metadata can enhance their work by making content easier to manage and share.
- IT Professionals: Even if you’re more tech-savvy, understanding metadata can improve how you manage systems and databases.
Overview of What’s to Come
Over the next few sections, we’ll break down everything you need to know about metadata. We’ll start by digging into the fundamentals—what it is and how it works. Then, we’ll explore different types of metadata and the standards and tools used to create and manage it. Expect practical examples along the way, including tables, code blocks, and even a few graphs to illustrate key points.
We’ll also discuss how metadata applies in various digital environments, such as web pages, multimedia files, and even social media platforms. Later, we’ll touch on more advanced topics like how metadata is used in artificial intelligence and big data analysis. Finally, we’ll wrap up with some hands-on projects so you can start applying what you’ve learned right away.
Effects of Metadata on SEO
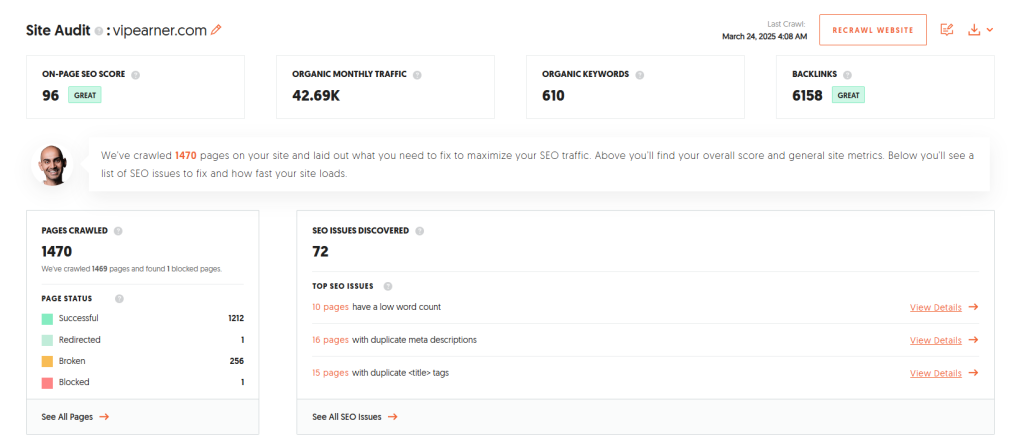
Metadata is more than just a behind-the-scenes organizer—it plays a crucial role in how search engines understand and rank your content. In this section, we’ll explore the direct impact metadata can have on SEO and why optimizing these details can make a real difference in your online visibility.
How Metadata Influences Search Engine Rankings
Search engines like Google use metadata to get a quick snapshot of what your content is about. Here’s how different types of metadata affect SEO:
- Title Tags:
The title tag is the clickable headline that appears in search results. A well-crafted title tag with relevant keywords not only informs users about your page’s content but also signals to search engines which topics your page covers. - Meta Descriptions:
Although meta descriptions don’t directly influence rankings, they can impact click-through rates. A clear, concise, and compelling meta description encourages users to click your link over others. Think of it as the mini-advertisement for your page in the search results. - Header Tags (H1, H2, H3):
These tags help structure your content and indicate the hierarchy of information. Search engines use header tags to understand the organization of your content, which can improve the readability and accessibility of your page. - Alt Text for Images:
Descriptive alt text for images not only improves accessibility for visually impaired users but also helps search engines understand what the image represents. This can boost your chances of appearing in image search results.
The SEO Benefits of Well-Managed Metadata
Optimizing metadata can provide several key benefits for your SEO efforts:
| Benefit | Description |
|---|---|
| Improved Visibility | Clear metadata helps search engines correctly index your pages, potentially boosting rankings. |
| Enhanced User Experience | Well-organized metadata (like header tags and alt text) makes your content more accessible and engaging. |
| Increased Click-Through Rates | Compelling meta descriptions and title tags encourage more users to click through to your site. |
| Better Content Organization | Structured metadata allows search engines to better understand and categorize your content. |
Best Practices for Metadata Optimization
To ensure your metadata is boosting your SEO instead of holding it back, consider these best practices:
- Keep It Relevant:
Use keywords naturally in your title tags and meta descriptions. Avoid keyword stuffing, which can hurt your rankings. - Stay Concise:
Title tags should typically be under 60 characters, and meta descriptions should aim for around 150–160 characters. This ensures that your metadata isn’t cut off in search results. - Be Descriptive:
Clearly describe the content of your page. Users should be able to tell what to expect before clicking the link. - Update Regularly:
As your content evolves, make sure your metadata stays current. Regular audits can help you catch outdated or irrelevant information. - Use Structured Data:
Consider implementing structured data (like schema markup) to provide even more context to search engines about your content. This can enhance your search result listings with rich snippets.
Real-World Examples
Imagine you run a blog about photography. If your images have well-optimized alt text and your articles have clear title tags and meta descriptions, search engines can quickly understand your content. This means when someone searches for "best landscape photography tips," your post is more likely to appear in the search results, and users will be drawn to your engaging meta description.
On the flip side, if your metadata is missing or poorly optimized, your pages may not rank as well, and users might bypass your content in favor of competitors who have taken the time to optimize these details.
In summary, metadata is a critical component of SEO. By ensuring that every element—from title tags to meta descriptions and alt text—is carefully optimized, you can improve your site’s visibility, enhance user experience, and drive more traffic to your content.
Metadata Management: What This Means For You

Metadata might sound like a buzzword, but at its core, it’s simply extra information that describes or explains something else. If you’ve ever labeled a moving box with “kitchen stuff” or “winter clothes,” you’ve already used a form of metadata. It’s the detail that helps you figure out what’s inside without having to rip open every box. In this section, we’ll walk through where metadata came from, clarify some basic terms, and explore the main categories you’ll run into.
A Brief History of Metadata
Think back to the days of card catalogs in libraries. Each card acted as a shortcut to a specific book, noting details like the author, title, and publication date. This was an early form of metadata—labels for physical objects. As technology advanced, those catalog cards turned into digital records, paving the way for systems that could store and share these details on computers.
In the 1960s, libraries adopted MARC (Machine-Readable Cataloging) to systematically organize their collections. This allowed catalog information to be read by machines instead of just humans. Later, standards like Dublin Core emerged in the mid-1990s to label digital resources (web pages, PDF files, images) in a straightforward, consistent manner. Today, metadata is everywhere—from the date and time stamps on your smartphone photos to the “track name” and “artist” fields in your music library.
Core Definitions and Terminology
It helps to get comfortable with a few key terms:
- Data vs. Metadata
Data is the actual content (like the text of an article). Metadata describes that content (like the article’s title or author). - Schema
A schema is a structured framework that tells you which pieces of metadata are needed and how they should be organized. It’s like a blueprint for labeling. - Tag
A tag is a keyword or label applied to a piece of data to make it easier to find later (think hashtags on social media). - Attribute
An attribute is a specific property or characteristic of the data. For a photograph, “resolution” could be an attribute that tells you how detailed the image is.
Types of Metadata
Metadata can be broken down into different categories based on what it does and how it’s used. Here’s a quick overview in table form:
| Type | Purpose | Examples |
|---|---|---|
| Descriptive | Helps identify and locate content | Titles, keywords, captions, author names |
| Structural | Shows how parts of a resource fit together | Chapters in a book, sections of a website, file hierarchy |
| Administrative | Manages and preserves the resource | Creation date, rights information, technical details |
| Specialized | Serves niche or industry-specific needs | Geospatial (location data), Preservation (archiving info), Statistical (data collection methods) |
Descriptive Metadata is what you’ll see most often. If you have a family photo, you might label it with a short caption (“Birthday Party”) and keywords (“family,” “party,” “2019”). These labels make it easier to search for later.
Structural Metadata is like a roadmap. If you have a multi-part resource (such as an ebook with multiple chapters), structural metadata connects each part so you know how they fit together. Without it, navigating a large digital collection would be like wandering around a city with no street signs.
Administrative Metadata covers the behind-the-scenes details, like who owns the file, when it was created, and which software was used. This is crucial for managing rights, tracking revisions, and preserving files for the long term.
Specialized Metadata comes into play for specific industries or use cases. For example, geospatial metadata includes map coordinates for satellite images, while preservation metadata might track the file formats and hardware needed to ensure a resource remains usable over decades.
That’s the big picture of what metadata is, where it started, and how it’s typically categorized. By understanding these basics, you’ll be ready to tackle more detailed topics—like choosing the right metadata standard or embedding metadata in your own projects. The best part is that once you see how metadata works, you’ll start noticing it everywhere, from the songs on your playlist to the products in your online shopping cart.
Metadata Standards and Frameworks

The reason metadata feels so powerful is that it doesn’t just label individual files; it also connects entire systems. Standards ensure that metadata created in one environment can be read and understood in another. Without consistent frameworks, you’d have a digital Tower of Babel, where each system speaks its own language and can’t share information effectively.
Importance of Standards
When you’re dealing with large collections of digital objects—anything from photos to research papers—you want a system that keeps everything organized in a predictable way. Metadata standards do just that. They define the fields, the naming conventions, and the structure of the information so that any compatible system can interpret it. This leads to:
- Interoperability: Imagine uploading your images from one software platform to another. If both platforms follow the same metadata standard, your tags, descriptions, and technical details remain intact.
- Consistency: It’s much easier to maintain accurate records when everyone follows the same rules. This is crucial for libraries, museums, or any organization managing massive collections.
- Long-Term Usability: Technology changes over time. A solid standard increases the chances that your metadata will still be usable and readable years from now.
Common Metadata Standards
Let’s explore a few of the most widely used standards. Each was developed for a specific purpose, so picking the right one often depends on your project’s focus.
Dublin Core
Dublin Core is like the Swiss Army Knife of metadata standards. It’s simple, flexible, and widely adopted. Originally created to describe web resources, Dublin Core includes 15 basic elements—like Title, Creator, Subject, and Date—that you can adapt to almost any digital resource.
<details> <summary>Example Dublin Core Elements</summary>
vbnetCopydc:title "Introduction to Metadata"
dc:creator "Jane Doe"
dc:subject "Metadata basics, Data organization"
dc:description "A beginner-friendly guide to understanding metadata."
dc:date "2025-03-27"
dc:type "Text"
dc:format "PDF"
dc:identifier "http://example.com/intro_to_metadata.pdf"
dc:language "en"
dc:rights "CC BY-NC 4.0"
</details>
You might see Dublin Core used by academic repositories, government websites, and digital libraries that want a lightweight yet structured approach.
EXIF
If you’ve ever checked the properties of a photo on your phone or camera, you’ve probably seen EXIF data. EXIF (Exchangeable Image File Format) was developed for image files to store technical details like:
- Camera model and manufacturer
- Shutter speed, aperture, and ISO settings
- Date and time the photo was taken
- GPS coordinates (if location services were on)
This metadata is embedded directly into the image file, making it easy for photo editing software to read and display these details. EXIF is essential for photographers who want to track their camera settings or for anyone organizing large photo collections by date or location.
IPTC
IPTC (International Press Telecommunications Council) metadata is a favorite in journalism and media. It helps news agencies and photographers attach key information to images, such as:
- Headline or Title: Brief description of the image content
- Caption: Detailed explanation of what’s happening in the image
- Keywords: Searchable terms to categorize the photo
- Credit Line: Photographer’s name or agency
Because IPTC fields are recognized across major photo management tools, they’re crucial for ensuring that editorial images are accurately labeled and credited.
MARC and RDA

In the library world, MARC (Machine-Readable Cataloging) is the granddaddy of digital cataloging. It’s been around since the 1960s, and it paved the way for consistent, machine-readable records of library collections.
- MARC Records: Contain fields for authors, titles, subjects, and publication info, all coded in a very structured format (like
245for title information). - RDA (Resource Description and Access): A newer set of guidelines that refines cataloging rules and makes them more compatible with the digital age. It builds on the foundation of MARC but aims to better handle non-book materials like ebooks and multimedia.
These standards may feel more complex than others, but they’re a cornerstone of library science, making it possible for libraries worldwide to exchange catalog information seamlessly.
Other Frameworks
Sometimes you’ll come across specialized frameworks that cater to very specific needs:
- METS (Metadata Encoding and Transmission Standard): Often used for complex digital objects, like multi-page documents or multimedia collections, to encode both the structural and descriptive metadata.
- PREMIS (Preservation Metadata): Focuses on long-term preservation, detailing the steps and conditions needed to keep a digital resource accessible over time.
Choosing the Right Standard for Your Project
Selecting the best standard can feel daunting, but it boils down to a few practical considerations:
- Content Type: Are you dealing with images, text, audio, or a combination of media? If it’s mostly images, EXIF and IPTC might be your go-to. For a library of ebooks, Dublin Core or MARC could be more fitting.
- Complexity vs. Simplicity: Some standards (like Dublin Core) are relatively simple to implement. Others (like MARC) can be more involved but offer deeper, more structured detail.
- Industry Requirements: Different fields often have their own preferred standards. Journalists lean on IPTC, while libraries rely on MARC/RDA.
- Interoperability Needs: If you plan to share your metadata with other organizations or platforms, choosing a well-known, widely supported standard helps avoid headaches later on.
Ultimately, metadata standards are there to make your life easier in the long run. By adhering to a well-established framework, you’ll ensure that your data remains consistent, shareable, and future-proof. That’s the real power of metadata standards and frameworks—connecting people, systems, and information in a way that just works.
How to Create and Manage Metadata

Creating and managing metadata might sound complicated, but once you have the right techniques and tools, it becomes a natural part of your workflow. In this section, we’ll explore different ways to generate metadata (both manually and automatically), introduce some popular management systems, walk through a simple example, and point out common pitfalls to avoid—all while highlighting how tools like a metadata editor, a metadata deleter, and a metadata extractor can fit into your process.
Two Approaches to Generating Metadata
One of the first decisions you’ll face is how to get metadata into your files. Do you rely on human effort or let software do the heavy lifting?
- Manual Approach: A person or team enters details like the title, author name, keywords, or descriptions. This method offers complete control over accuracy but can be time-consuming. It’s best suited for smaller collections or when precise, human-curated information is critical. Here’s where a metadata editor tool becomes useful—it provides a straightforward interface to add, modify, and organize metadata fields.
- Automated Approach: Tools known as metadata extractor software can read embedded information directly from files. For example, a photo might already have EXIF data with camera settings, date, and location. Automated methods save time, especially if you have thousands of files. However, they can’t capture context-specific details like a custom caption or a nuanced description—those still need a human touch.
Metadata Management Systems
Once your metadata is created, you’ll need a system to organize and maintain it. There are many platforms available, each with its own strengths:
- Content Management Systems (CMS): Popular for websites and blogs. They typically have fields for tags, categories, and descriptions, making it easy to sort and filter content.
- Digital Asset Management (DAM) Systems: Designed for large volumes of media files (images, videos, audio). They often include automated tagging, bulk editing, and advanced search features. Many DAM systems also have built-in metadata editors for quick updates.
- Library Management Software: Focused on structured records, especially for ebooks, research papers, or historical archives. These systems handle complex metadata fields like MARC records.
Key Features to Consider:
- Customization: Can you add fields specific to your organization’s needs?
- Integration: Will the system work smoothly with your existing workflows or tools?
- Reporting: Some platforms offer dashboards to monitor metadata coverage and quality.
A Hands-On Example
Let’s say you have a folder of photos from a recent event and you want to categorize them:
- Import Your Photos: Bring them into a DAM or photo management tool.
- Apply a Metadata Extractor: Automatically pull EXIF data (like date taken and camera model).
- Use a Metadata Editor: Add or refine custom fields such as a descriptive title, event name, or any special tags that automation might miss.
- Save and Organize: Confirm everything is correct and consistent. Once done, your photos will be much easier to search and sort.
Below is a simple JSON-style snippet showing how these details might look:
jsonCopy{
"imageTitle": "Team Building Retreat",
"dateTaken": "2025-07-10",
"keywords": ["team", "retreat", "outdoors", "fun"],
"description": "Company retreat activities at the lakeside cabin."
}
Editing and Maintenance
Metadata isn’t a “set it and forget it” deal. Over time, you might need to remove outdated tags or correct mistakes. This is where a metadata deleter can help by stripping away fields that no longer make sense—especially important if you need to clear sensitive information or stay compliant with privacy regulations.
Tips to Keep Things Tidy:
- Scheduled Audits: Periodically review a subset of files to ensure everything is labeled correctly.
- Version Control: Keep track of changes so you know who edited what and when.
- Bulk Updates: Many DAM systems let you edit multiple files at once, which is a huge time-saver for large collections.
Challenges and Pitfalls
Even the best metadata plan can go off the rails if you’re not careful:
- Inconsistent Terminology: If one person tags images as “NYC” while another uses “New York City,” your search results might get split.
- Excessive or Irrelevant Tags: Adding too many keywords can clutter your system and make searching less efficient.
- Lack of Governance: Without a clear policy on how to manage metadata, errors can multiply quickly.
- Over-Reliance on Automation: While a metadata extractor is great, it won’t capture context-specific details. Human review remains essential.
By striking the right balance between manual input and automation—and by staying on top of edits—you’ll keep your metadata accurate, useful, and ready to adapt as your projects evolve. A well-chosen metadata editor or deleter can make all the difference, ensuring that your digital resources remain clean, searchable, and organized.
How Metadata Powers Search, Analytics, and AI

Metadata isn’t just about organizing files—it’s the key that unlocks powerful search, deeper analytics, and even more accurate AI models. By adding context and structure to raw data, metadata helps machines and humans alike find the right information at the right time.
In this section, we’ll look at how metadata enhances discovery in search engines and digital libraries, how it supports data analytics, and how it feeds the algorithms behind artificial intelligence and machine learning. We’ll also explore real-world success stories that show the impact of a solid metadata strategy.
Enhancing Search and Discovery
When you type a query into a search engine, you’re counting on it to serve up the most relevant results in seconds. That magic happens, in part, because of metadata:
- Web Pages: Search engines look at HTML tags—such as the title tag and meta description—to understand what each page is about. These tags provide quick context, so the search engine doesn’t have to parse the entire page before deciding if it’s relevant.
- Digital Libraries: Librarians and archivists rely on structured metadata (like author, publication date, and subject headings) to catalog books, articles, and multimedia. This organization makes it simple to locate items, even if the collection spans millions of records.
Without metadata, finding what you need online would be like rummaging through an unmarked warehouse. By labeling content accurately, metadata ensures that search engines and library catalogs can deliver precise results in a fraction of the time.
Metadata and Data Analytics

Data analytics is all about turning raw information into actionable insights, and metadata plays a crucial role in making that happen:
- Contextual Clarity: Imagine you have a spreadsheet with thousands of rows of numbers. Without metadata explaining what those numbers represent—sales figures, survey responses, sensor readings—it’s just a jumble of digits.
- Efficient Queries: Metadata tags let analysts quickly sort or filter datasets. For example, if a retail chain wants to analyze sales by region, it helps to have each transaction tagged with a location attribute.
- Better Decision-Making: By attaching clear labels and descriptions to your data, you can run more sophisticated analyses. This leads to insights that might have stayed hidden if you had to rely on guesswork or incomplete documentation.
In short, metadata acts like a roadmap for your data, telling you where to look and how different pieces fit together. The clearer your roadmap, the faster and more accurately you can draw conclusions.
Metadata in Artificial Intelligence and Machine Learning
AI and machine learning models thrive on structured data. The more organized and well-labeled your datasets are, the easier it is for algorithms to learn patterns and make predictions:
- Training Data: Machine learning models rely on labeled examples to recognize patterns. Metadata provides those labels—like identifying a photo as a “cat” or “dog,” or tagging an email as “spam” or “not spam.”
- Feature Engineering: Sometimes, metadata can become the most valuable features in a model. For instance, timestamps or geolocation tags might reveal trends that raw text or numeric data alone wouldn’t show.
- Model Performance: Poorly labeled or incomplete metadata can lead to skewed results. Accurate metadata ensures the training data reflects real-world scenarios, giving your AI models a better chance at success.
From recommendation engines to image recognition, metadata is often the secret ingredient that helps AI figure out what’s what. Without it, machines are left to guess, which usually leads to less reliable outcomes.
Real-World Impact
Plenty of organizations have seen dramatic improvements in searchability, analytics, and AI performance thanks to a solid metadata strategy:
- E-Commerce: Online retailers use metadata to personalize product recommendations, track inventory by category, and improve their on-site search experience. This can boost sales by showing customers exactly what they’re looking for.
- Healthcare: Hospitals and research institutions attach detailed metadata to patient records, medical images, and research data. This not only makes it easier to find the right files but also paves the way for machine learning tools that can detect early signs of diseases.
- Media and Entertainment: Streaming platforms use metadata to categorize shows and movies by genre, cast, and rating, ensuring you see relevant suggestions. Behind the scenes, metadata also helps in rights management and content licensing.
In each case, the common thread is metadata. By making data discoverable, analyzable, and machine-friendly, organizations can streamline operations, drive better decisions, and deliver more personalized experiences. It’s not just about labeling files—it’s about unlocking the full potential of your digital assets.
Legal, Ethical, and Privacy Considerations

Metadata can reveal a surprising amount of information about individuals, organizations, and even entire industries. While this data is invaluable for everything from research to AI, it also raises important questions about privacy, ownership, and compliance. In this section, we’ll explore how to protect personal metadata, navigate copyright concerns, handle ethical dilemmas, and comply with relevant laws and regulations.
Privacy and Security Concerns
Even something as simple as a timestamp or a location tag can paint a detailed picture of a person’s life. When you collect metadata, you might be capturing:
- Location Data: GPS coordinates or IP addresses can track someone’s movements or whereabouts.
- Behavior Patterns: Time stamps and usage logs might show when people are active online, what devices they use, or how they interact with certain apps.
- Personal Identifiers: Email addresses, usernames, and phone numbers are often stored in metadata, linking an individual to a piece of content.
To protect this information, organizations and individuals should consider encrypting metadata at rest and in transit. Access controls—such as passwords, multi-factor authentication, and role-based permissions—help ensure that only authorized users can view or edit sensitive details. It’s also crucial to implement data retention policies that clearly define how long metadata is kept and under what conditions it can be deleted or anonymized.
Copyright and Intellectual Property

Metadata can contain copyrighted material or be used to assert rights over a work. For instance, photographers often embed ownership details in the metadata of their images, while authors might include their names and publication details in document metadata.
- Attribution: Proper metadata ensures creators get credit for their work, which can be vital for both ethical and legal reasons.
- Fair Use vs. Infringement: In some cases, metadata might reveal unauthorized usage—like someone else claiming ownership or distributing a work without permission.
- Licensing: Many creative works are governed by specific licenses (e.g., Creative Commons). Embedding license information in metadata clarifies what others can and can’t do with the content.
Navigating these complexities often involves consulting with legal experts, especially if you’re dealing with large-scale or commercial projects. The goal is to ensure that metadata doesn’t inadvertently violate copyright laws or enable others to misuse intellectual property.
Ethical Considerations
When you collect and store metadata, you’re effectively gathering insights about people’s habits, preferences, and sometimes even their identities. This raises ethical questions about:
- Data Ownership: Who truly “owns” metadata—the creator of the content, the platform hosting it, or the individual whose data is being recorded?
- Consent and Transparency: It’s important to inform users that their metadata is being collected, explain how it will be used, and offer them the option to opt out if possible.
- Minimization: Ethical data practices often involve collecting only the metadata you need and discarding anything unnecessary to reduce potential risks.
Building trust means being transparent about why you collect metadata and how it benefits users. Whether you’re running a website or an app, clear privacy policies and user-friendly consent mechanisms are a must.
Regulations and Compliance
Governments worldwide are paying closer attention to data protection. Depending on your location and the nature of your data, you may need to comply with:
- GDPR (General Data Protection Regulation): Enforces strict rules on data handling for organizations that operate in or do business with the EU. It emphasizes user consent, the right to be forgotten, and clear communication about data usage.
- CCPA (California Consumer Privacy Act): Similar in spirit to GDPR but focused on California residents, granting them greater control over how their personal information is collected and shared.
- Industry Standards: Some sectors have specialized guidelines (e.g., HIPAA in healthcare) that dictate how sensitive data, including metadata, should be stored and transmitted.
Staying compliant involves regular audits, clear documentation of data flows, and up-to-date privacy policies. Ignoring these regulations can lead to hefty fines and reputational damage, so it’s worth investing in a thorough compliance strategy.
By taking privacy, intellectual property, ethics, and regulatory requirements seriously, you’ll not only avoid legal pitfalls but also build a foundation of trust with your users and stakeholders. Proper metadata handling is about more than just data—it’s about respecting the people behind it.
Mastering Advanced Metadata
Once you’ve mastered the basics—understanding what metadata is, how to create it, and how to manage it—there’s a whole world of more advanced concepts waiting to be explored. In this section, we’ll look at how metadata can power the Semantic Web, how different systems exchange metadata seamlessly, and where metadata is headed next. We’ll also dig into how metadata plays a huge role in handling massive datasets.
Semantic Metadata and Linked Data
RDF, OWL, and the Semantic Web
Imagine you have a bunch of puzzle pieces scattered across the internet—webpages, databases, and APIs. The idea behind semantic metadata is to create a system where all these pieces fit together in a meaningful way, even if they come from different sources. That’s where RDF (Resource Description Framework) and OWL (Web Ontology Language) come into play:
- RDF: Provides a model for describing resources in a subject-predicate-object format, often referred to as “triples.” It’s like saying “Subject (my dog) – Predicate (is a) – Object (German Shepherd).” By standardizing this format, RDF lets different systems interpret data consistently.
- OWL: Builds on RDF by offering a richer language for defining relationships and classes. For example, you can define a class of “Dogs,” and state that “German Shepherd” is a subclass of “Dogs.” This helps machines reason about the data, not just store it.
The Semantic Web aims to make data understandable by both humans and computers, enabling automated systems to make more intelligent connections. For instance, if you have metadata describing a historical figure on one website and a related event on another, the Semantic Web can link those details together—offering context that would otherwise stay hidden.
Metadata Interoperability
How Different Systems Communicate and Share Metadata
In a perfect world, every database, app, and platform would speak the same metadata language. In reality, there are countless standards and formats. That’s why metadata interoperability is such a hot topic. It’s all about ensuring that metadata created in one system can be understood and used by another.
- Crosswalks: These are mappings between different metadata schemas. For instance, if you have a field called “Creator” in Dublin Core, you might map it to “Author” in another standard.
- APIs and Protocols: Tools like OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting) allow repositories to share metadata in a standardized way.
- Bridging Old and New Systems: Libraries often deal with MARC records, while digital repositories might use Dublin Core. Metadata interoperability solutions help them exchange data without losing important details.
By focusing on interoperability, organizations can pool resources, reduce duplication, and create richer collections of information—making the user experience far smoother.
Future Trends in Metadata
Emerging Technologies and the Evolution of Metadata Practices
Metadata isn’t static. As technology evolves, new trends emerge:
- AI-Driven Metadata Generation: Machine learning models can automatically tag content, transcribe audio, or categorize images based on visual cues. This speeds up the cataloging process and reduces human error, though it still needs oversight.
- Blockchain for Metadata Verification: Some are exploring the idea of storing metadata in a blockchain for tamper-proof records. This could be especially useful for proving the authenticity and ownership of digital assets.
- Context-Aware Metadata: Beyond basic tags and descriptions, metadata might include user context (like device type, location, or previous interactions). This can personalize search results or recommendations in real time.
- Augmented Reality and Virtual Reality: As immersive technologies gain ground, new types of metadata will be needed to describe 3D objects, interactive scenes, and user interactions within these environments.
These trends hint at a future where metadata is not just about organization but also about enhancing user experiences, ensuring authenticity, and adapting to a rapidly changing digital landscape.
Metadata and Big Data

The Role of Metadata in Managing and Analyzing Large Data Sets
When dealing with enormous data sets—think millions or billions of records—metadata becomes your lifeline. It helps analysts figure out:
- Where the data came from (provenance).
- How it’s structured (schema).
- What each column or field actually means (semantic context).
Without well-defined metadata, big data projects can quickly turn into a mess. You might have thousands of columns in a data warehouse but no clear explanation of what each one represents. This is like trying to read a map with no legend. By tagging datasets with consistent, clear metadata, data scientists and analysts can:
- Run Queries More Efficiently: Metadata indicates which fields are relevant for certain calculations.
- Prevent Mistakes: Knowing the origin and quality of data helps avoid mixing incompatible data sets or using outdated information.
- Enable Automation: AI-driven tools can more easily interpret and analyze data if they understand each field’s purpose.
In the realm of big data, metadata is often the difference between meaningful insights and wasted processing power. It provides the structure and context that turn raw numbers into actionable knowledge.
By delving into semantic metadata, ensuring interoperability, keeping an eye on emerging trends, and leveraging metadata to wrangle big data, you’re positioning your organization (and yourself) at the forefront of digital information management. Metadata might seem like a simple concept at first, but as you explore these advanced topics, it becomes clear that it’s the backbone of an increasingly connected and intelligent world.
Essential Tools and Technologies for Metadata Professionals
Whether you’re wrangling a small library of images or managing an enterprise-scale data repository, the right tools can make all the difference. In this section, we’ll compare open source and commercial software, explore some hands-on tutorials, and look at how to integrate these solutions into your existing workflows.
Open Source vs. Commercial Tools
Deciding between open source and commercial tools often comes down to budget, technical expertise, and project requirements. Here’s a quick look at both sides:
- Open Source Solutions
- Pros: Typically free to use and highly customizable. The community-driven nature often leads to rapid feature development and a wealth of user-contributed documentation.
- Cons: May require more technical expertise to set up and maintain. Official support can be limited or rely on community forums.
- Examples:
- DSpace: Popular in academic and research institutions for managing digital repositories.
- Apache Tika: Great for extracting metadata from a wide range of file formats.
- Commercial Software
- Pros: Comes with dedicated customer support, regular updates, and often a user-friendly interface. Many commercial tools also integrate seamlessly with other enterprise systems.
- Cons: Licensing fees can be significant, and customization might be restricted by the vendor’s roadmap.
- Examples:
- Adobe Experience Manager (AEM) Assets: Offers robust digital asset management features with built-in metadata capabilities.
- Bynder: Provides cloud-based DAM services with automated tagging and streamlined workflows.
Software Tutorials and Demos
Hands-on learning is one of the best ways to understand a tool’s strengths and weaknesses. Many platforms offer free trials, demo videos, or interactive sandboxes:
- Walkthrough Videos: Look for official YouTube channels or community-made tutorials that show how to configure metadata fields, set up user permissions, or create workflows.
- Documentation Hubs: Most open source projects have a wiki or GitHub repository with step-by-step guides. Commercial vendors often have knowledge bases or live chat support for troubleshooting.
- Community Webinars: Keep an eye out for webinars hosted by developers or power users. They often include Q&A sessions, which can be invaluable if you’re dealing with a tricky setup.
Integrating Metadata Tools into Existing Workflows
No matter how feature-rich your chosen tool is, smooth integration into your current processes is key. Here are a few strategies:
- Start Small: Pick a pilot project—maybe a subset of your files—to test out the tool. This allows you to identify hiccups without risking your entire repository.
- Map Out Your Needs: Before integrating, clarify which metadata fields matter most to your team. This will guide how you configure the tool and ensure everyone is on the same page.
- Automate Where Possible: Many tools offer APIs or batch processing capabilities. Automating tasks like bulk tagging or metadata extraction can save a lot of time.
- Train Your Team: A short onboarding session can prevent confusion down the road. Show your colleagues how to add or edit metadata and demonstrate any relevant reporting features.
By taking the time to compare open source and commercial options, experimenting with demos, and planning a careful rollout, you’ll set yourself up for success. After all, a well-chosen metadata tool isn’t just software—it’s a cornerstone of your entire data management strategy.
How Can I Practice Using Metadata?

Working with metadata can feel theoretical until you roll up your sleeves and dive in. Below are a few hands-on exercises that will help you practice what you’ve learned, whether you’re working solo or in a group. We’ll also cover some common pitfalls and point you toward resources for troubleshooting.
Creating a Personal Metadata Project
A simple way to get started is by cataloging your own digital library—maybe it’s a collection of ebooks, photos, or music files. Here’s a step-by-step outline:
- Choose Your Focus: Pick a specific type of media (e.g., PDFs, photos, or audio files).
- Gather Your Files: Place them in a single folder or directory for easy access.
- Decide on Key Fields: Think about which metadata fields matter most. For ebooks, it might be title, author, publication date, and genre. For photos, consider date taken, location, and keywords.
- Select a Tool: You can use a spreadsheet, a simple DAM system, or even a metadata editor that supports batch processing.
- Add or Extract Metadata: If your files have embedded metadata (like EXIF for photos), extract it automatically. Then manually fill in any missing fields.
- Review and Refine: Spot-check a few entries to ensure everything is consistent. Look for typos or mismatched tags.
By the end of this exercise, you’ll have a mini-library that’s much easier to search, sort, and share. Plus, you’ll get a feel for which metadata fields are genuinely useful—and which ones you can skip.
Group Projects and Collaborative Metadata Work
Working with a team adds a new layer of complexity, but it can also be more rewarding. Here’s how to approach group metadata projects:
- Define Roles and Responsibilities: Who’s responsible for data entry? Who approves final tags or fields? Clear assignments prevent duplication and confusion.
- Set Standards Early: Agree on a naming convention and decide on controlled vocabularies to maintain consistency.
- Use Shared Tools: A collaborative platform—like a shared spreadsheet or a cloud-based DAM—lets everyone contribute in real time.
- Regular Check-Ins: Schedule short meetings or Slack updates to confirm progress and address any snags.
This collaborative approach is especially useful if you’re managing large collections or need multiple perspectives to accurately label your files.
Troubleshooting Common Issues
Even the most well-planned metadata project can hit snags. Below is a table outlining typical problems, possible causes, and recommended solutions:
| Issue | Possible Cause | Fix or Workaround | Resources |
|---|---|---|---|
| Inconsistent Tagging | Different team members using varied terms (e.g., “NYC” vs. “New York”) | Create a controlled vocabulary or standardized list of tags; run a bulk update to fix labels | Official documentation for your DAM system; community forums for best practices on naming conventions |
| Missing or Corrupted Metadata Fields | Metadata extractor tool fails to pull all details or format is unsupported | Manually fill in missing fields; try a different extractor that supports your file format | GitHub repos for open source extractors (e.g., Apache Tika); vendor support for commercial tools |
| Outdated Metadata | No regular schedule for reviewing and updating tags or fields | Set up periodic audits; enable version control to track changes and revert if needed | Internal documentation on update policies; workflow automation features in your DAM/CMS |
| Overloaded or Irrelevant Tags | Too many keywords added in an attempt to cover all bases | Establish tagging guidelines to keep metadata concise and relevant; remove duplicates | Official style guides or metadata frameworks (e.g., Dublin Core guidelines) |
| Lack of Governance | No clear policy on how metadata should be handled, leading to confusion | Draft a metadata governance policy; assign roles for oversight and compliance | Company policies; legal/compliance guidelines (e.g., GDPR requirements for data management) |
When in doubt, lean on community resources such as official forums, GitHub issues (for open source projects), and vendor support (for commercial platforms). By addressing these issues head-on, you’ll keep your metadata project running smoothly and ensure that your data remains accurate, searchable, and up to date.
Conclusion
We've explored a comprehensive range of metadata topics, from fundamentals to advanced concepts like semantic metadata, interoperability, and its role in big data and AI. We've covered creation, management, legal and ethical aspects, and tools for streamlining the process, along with practical exercises for hands-on learning.
Metadata's significance will continue to grow, particularly in AI-driven solutions and the development of the Semantic Web. Emerging technologies like AR and VR will present new challenges and opportunities for metadata management.
Apply your knowledge by experimenting with metadata tools on personal files or proposing a pilot project at work. Try open-source options like DSpace or Apache Tika, or explore commercial DAM platforms. Remember to establish clear standards for consistency, especially in collaborative environments.
Share your experiences, challenges, and insights about metadata in the comments. Your feedback contributes to community learning and drives innovation in the field.
Glossary of Metadata Terms

Below is an expanded list of common terms you’ll encounter when working with metadata, from foundational concepts to specialized standards.
Administrative Metadata
Information used for management, such as creation date, file format, and access rights. This type of metadata helps with version control, digital preservation, and resource administration.
Attribute
A specific property or characteristic of a resource. For example, “title” or “author” are attributes that describe a document.
Controlled Vocabulary
A predefined list of terms or phrases used to maintain consistency in tagging or categorizing resources (e.g., using “NYC” instead of “New York City” or “Big Apple”).
Crosswalk
A mapping between two different metadata schemas. Crosswalks allow data to be translated from one format to another without losing critical information.
Dublin Core
A widely used metadata standard with 15 core elements (like Title, Creator, Date) that can be applied to a broad range of digital resources.
EXIF (Exchangeable Image File Format)
A metadata standard for images, commonly used by digital cameras to store details such as shutter speed, date taken, and GPS coordinates.
IPTC (International Press Telecommunications Council)
A set of metadata standards frequently used in news media and photography to label images with headlines, captions, and credit information.
Interoperability
The ability of different systems, applications, or components to communicate and exchange data effectively. In metadata, this means one schema or format can be understood and used by another system.
MARC (Machine-Readable Cataloging)
A metadata standard primarily used by libraries to catalog books and other materials in a structured, machine-readable format.
Metadata
Data about data. It provides descriptive, structural, or administrative information that helps identify, manage, or locate a resource.
Metadata Editor
A tool or software interface used to create, modify, or delete metadata fields for a given file or resource.
Metadata Extractor
Software that automatically reads embedded metadata (e.g., EXIF data in images) and presents it in a human-readable form.
Metadata Governance
Policies and procedures that guide how metadata is created, maintained, and used across an organization. Good governance ensures consistency and compliance.
Ontology
In metadata and semantic web contexts, an ontology defines how different concepts relate to each other, providing a structured framework for organizing information.
OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting)
A protocol that allows repositories to expose their metadata, enabling other systems to harvest it. This is commonly used by digital libraries to share records.
OWL (Web Ontology Language)
A language designed to represent rich and complex knowledge about things, groups of things, and relations between things. It’s often used alongside RDF to enable reasoning about data.
Preservation Metadata
Metadata focused on ensuring the long-term usability of digital files, including information about file formats, fixity checks (e.g., checksums), and migration histories.
RDA (Resource Description and Access)
A newer set of guidelines for creating library metadata, building on MARC but designed to handle digital and non-book materials more effectively.
RDF (Resource Description Framework)
A standard model for data interchange on the web. It represents information in the form of triples—subject, predicate, and object—to describe resources and their relationships.
Schema
A blueprint or framework outlining which metadata fields are needed, how they’re structured, and what each field represents.
Semantic Web
An extension of the current web where information is given well-defined meaning through metadata standards like RDF and OWL, enabling computers and humans to work together more effectively.
Structured Metadata
Metadata organized in a fixed format, such as a spreadsheet or a database table. This contrasts with unstructured metadata, like free-text descriptions.
Tag
A keyword or label applied to a resource, often used to categorize or group similar items for easy retrieval.
Taxonomy
A hierarchical classification or arrangement of categories. In metadata, taxonomies help create a structured way to organize and label content.
Triple (RDF Triple)
The fundamental data structure in RDF, consisting of a subject, predicate, and object. For example: <Subject>—<Predicate>—<Object> might describe a file, its author, and the author’s name.
This glossary should give you a solid starting point for understanding the diverse terminology used in the metadata field. Each term plays a part in creating a cohesive, interoperable system where data is easily searchable, shareable, and maintainable.
